
合成数据是由机器而非人类创建的数据。它在机器学习和人工智能领域已经存在相当长一段时间了,因为它与数据增强技术密切相关。如今,合成数据旨在减少人类在人工智能制作过程中的参与,并使这个过程对他们来说更容易,正如 Anthropic 的训练方法和 OpenAI 新成立的 Superalignment 团队所展示的那样。
这篇博文讨论了 Nathan Lambert 关于人工智能中合成数据当前用途的精彩文章中涵盖的一些主题,并将它们与我们的 distilabel 人工智能反馈开源框架联系起来。您可以在此处阅读 Nathan 的博文。
合成数据会是下一个突破吗?
合成数据能带来下一个突破吗?支持使用合成数据的核心假设是规模:如果质量足够高,添加更多数据将使模型更好。我们认为,这可能需要人类的参与才能使其发挥作用。要获得足够的数据来训练比今天大一百倍的模型,将需要大量的合成数据。然而,也有反对它的论点:来自与当前最佳模型相同分布的合成数据不会推进技术水平。尽管如此,Nathan 认为当前的 GPT4 tokens 足以帮助 GPT5 突破界限。由于大型公司使用合成数据来向前发展和扩大规模,小型公司则依赖它,因为相同规模的真实数据要昂贵得多。合成数据也高度普及,因为它可以用于成熟的预测任务(如质量评级),也可以用于生成任务(如创建偏好数据集的选项)。
RLAIF 和 Anthropic 对合成数据的使用
Anthropic 开创了一种名为 Constitutional AI 的方法,这是迄今为止最大规模的已确认合成数据使用案例。这个概念可以概括为两个要点
- 当模型生成对问题的答案时,它会根据 Anthropic 员工策划的宪法中的原则列表检查答案,以使模型更有用且无害。
- LLM 用于生成偏好数据,我们使用它来对最佳完成项进行分类。然后,RLHF(来自人类反馈的强化学习)像往常一样使用合成数据进行,因此得名来自人工智能反馈的强化学习 (RLAIF)。
合成指令、偏好、评论和环路中的人类
像 Alpaca 和 Vicuna 这样的模型使用了合成指令数据来对 Llama 模型进行监督微调,使其在 7-13B 参数范围内达到令人印象深刻的性能。基础模型的空间已经变得非常密集,每周都有新模型问世。
许多开放指令数据集都在 Self-Instruct 风格的方法中得到改进,在这种方法中,可以创建一组“种子”指令,并使用 LLM 生成与它们类似的新指令。另一方面,必须小心,因为像 ShareGPT 这样的提示数据集的平均质量非常低且分布狭窄,这使得数据管理更加重要(查看 LIMA 论文 此处)。这就是 Argilla 和 distilabel 发挥作用的地方!distilabel 专注于合成数据生成,而 Argilla 有助于数据管理。
在 distilabel 中,Self Instruct 任务可以用几行代码定义。管道获取一组初始输入和一个应用程序将响应这些指令的类型的描述。与其他生成指令和响应的自指令方法不同,我们的方法仅生成指令。通过拆分指令和响应生成步骤,我们旨在避免其他方法显示的现有质量问题,在这些方法中,质量差和无意义的指令会导致不良响应。在 distilabel 中,您首先生成指令,管理它们(通过手动探索或以编程方式),然后使用它们通过文本生成或偏好 distilabel 管道生成多样化的响应。这些指令随后可以与偏好任务以及即将推出的评论任务一起使用,以生成人工智能反馈数据,这些数据反过来可以用于 LLM 对齐。
人类修订方法被用于创建 Notus,这是 Zephyr 的监督微调 (SFT) 版本的 7B DPO 微调版本。在开发 Notus 时,我们通过使用 Argilla 发现,评论的总体评分与响应质量之间存在很大的不匹配。生成了数据集的管理版本,并且模型经过微调,在两个基准测试中都超过了初始模型。
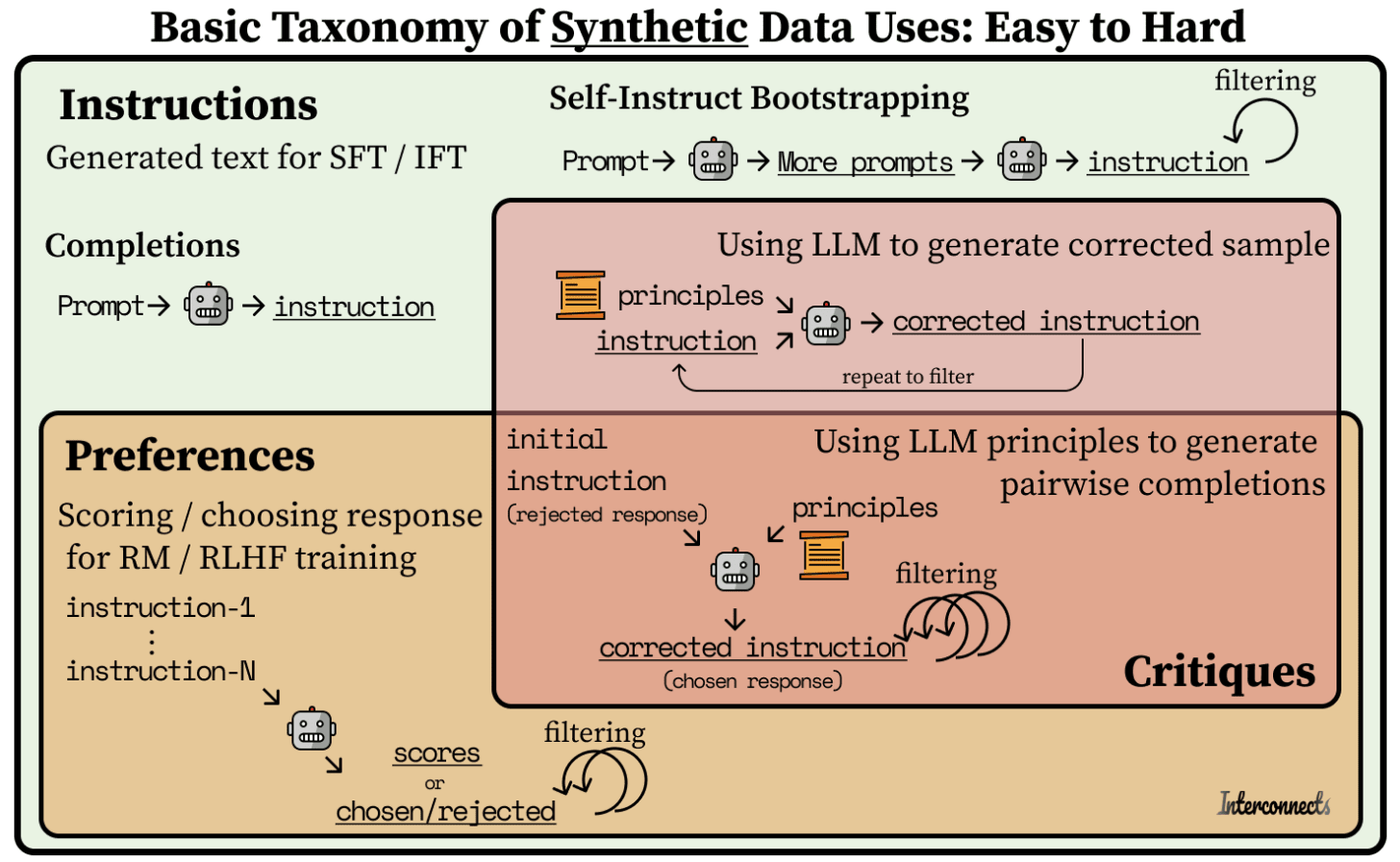
Nathan 认为,最终的前沿是使通过人工智能评论生成的偏好或指令数据成为可能:反复使用 LLM 针对特定原则或问题的过程。在过程中添加更多上下文使得模型对评论合成数据的先决条件能力更高。
distilabel 如何处理用于 LLM 微调的合成数据?
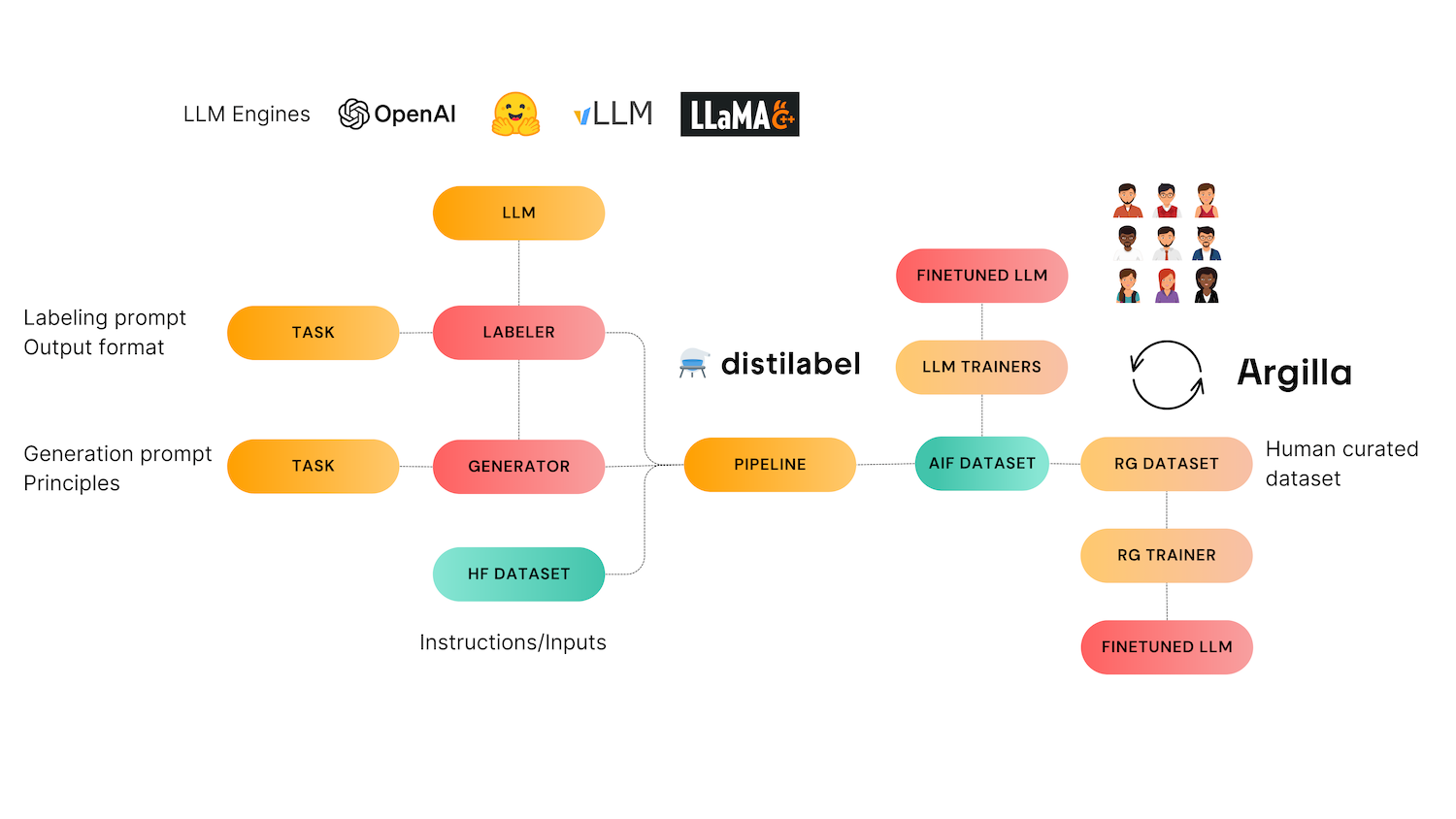
在这张图片中,我们可以看到 Nathan 用来突出显示合成数据不同用途的图表:从指令生成,到偏好,再到评论。Distilabel 是唯一一个大规模处理所有这些阶段的 OSS 框架。在研究文献和更实用的框架中,都有很棒的指令生成方法。我们的 Self Instruct 任务是有意简单的,旨在为那些没有指令/提示开始构建偏好数据集的从业者服务。偏好和评论模型是我们最重要的贡献和主要关注点。您可以使用任何指令生成机制,并且仍然可以从高性能偏好模型和任务中受益
- 它使用提示作为输入生成指令。
- 它可以从指令集中创建偏好数据集,这些指令集可以在管道中稍后评分或选择。
- 很快,它将能够将指令与原则(类似于 Anthropic 的宪法)结合起来,以创建经过纠正和改进的指令。
如果您喜欢这项工作并且对数据质量、AIF、LLM 和 NLP 感兴趣,请加入我们的 discord 并在我们的 repos 上留下一个 star:distilabel 和 argilla!


