
简介
这是关于人类反馈强化学习替代方案的一系列博客文章,由 Argilla 和 MantisNLP 团队共同努力创建。请确保您已阅读本系列之前的文章,以充分理解上下文和讨论的进展,然后再继续阅读本文。滚动到页面底部以转到本系列的下一篇博文。
在之前的文章中,我们首先分析了执行监督微调 (SFT) 和人类反馈强化学习 (RLHF) 的努力,以及拥有高质量数据的重要性(第一篇 和 第二篇 博文)。然而,RLHF 复杂且通常不稳定,因此我们研究了一种有前景的替代方案,即直接偏好优化 (DPO),以便在不需要强化学习的情况下使 LLM 与人类偏好对齐(第三篇 博文)。尽管如此,DPO 并不能解决所有缺点,例如,需要大量的偏好数据才能进行微调。为了解决这个问题,研究人员提出了新的方法。其中一些是人工智能反馈强化学习 (RLAIF) 或自博弈微调 (SPIN)(第四篇 和 第五篇 博文)。为了更好地对齐数据,我们还探讨了身份偏好优化 (IPO) 和卡尼曼-特沃斯基优化 (KTO) 的好处(第六篇 和 第七篇 博文)。还描述了 ORPO,因为它简化了对齐过程(第八篇 博文)。在 第九篇 博文中,我们概述了迄今为止提出的方法的优点和缺点。
在大多数情况下,我们处理的是所谓的偏好数据,我们在两个给定的选项之间选择一个答案。但是,如果我们必须在两对提示及其响应之间做出选择呢?这就是 DOVE 通过联合偏好优化提出的方案。
从条件偏好优化到联合偏好优化
语言模型通常依赖于基于排名的方法进行对齐。在这种方法中,基于固定的上下文比较对相同指令的响应。虽然这可能有效,但它也可能具有局限性,因为它未能充分捕捉人类偏好的多样性和变化性。DPO 就是这种情况,它一直是 LLM 对齐的首选策略。
实际上,人类偏好是基于更广泛的标准,也就是说,人类也会在不相同的上下文中表达偏好。例如,原始论文表明,在购买电子产品时,您可能更喜欢对产品的特性和用途进行结构化和详细描述的评论。但是,在查找电影评论时,您可能更喜欢那些更主观和更具表现力的评论。
因此,将坏苹果与好橙子进行比较:通过联合偏好优化对齐大型语言模型 的作者引入了一个新的框架,该框架改进了传统的基于排名的方法。这种方法不是基于相同的指令比较响应,而是比较指令-响应对。这使得模型能够捕捉语言方面(例如,对指令的遵守、语法流畅性和清晰度)以及更广泛的、依赖于上下文的人类偏好。
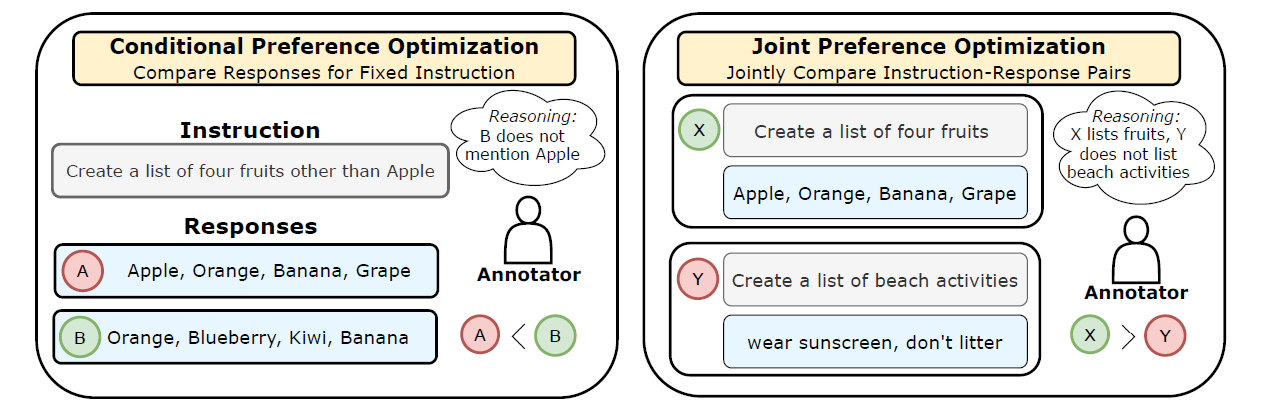 条件偏好优化和联合偏好优化之间的差异。来源:https://arxiv.org/abs/2404.00530
条件偏好优化和联合偏好优化之间的差异。来源:https://arxiv.org/abs/2404.00530
DOVE
为了实现联合偏好优化,引入了 DOVE 作为一个新的创新框架。DOVE 是一种偏好优化目标,旨在通过从指令-响应对的偏好中学习来对齐语言模型。
与 DPO 方法类似,DOVE 从监督微调的语言模型开始。然后,它专注于权衡首选响应相对于非首选响应的联合概率。这涉及调整首选响应相对于非首选响应的条件概率,以及基于语言模型指令的先验概率的校正因子。
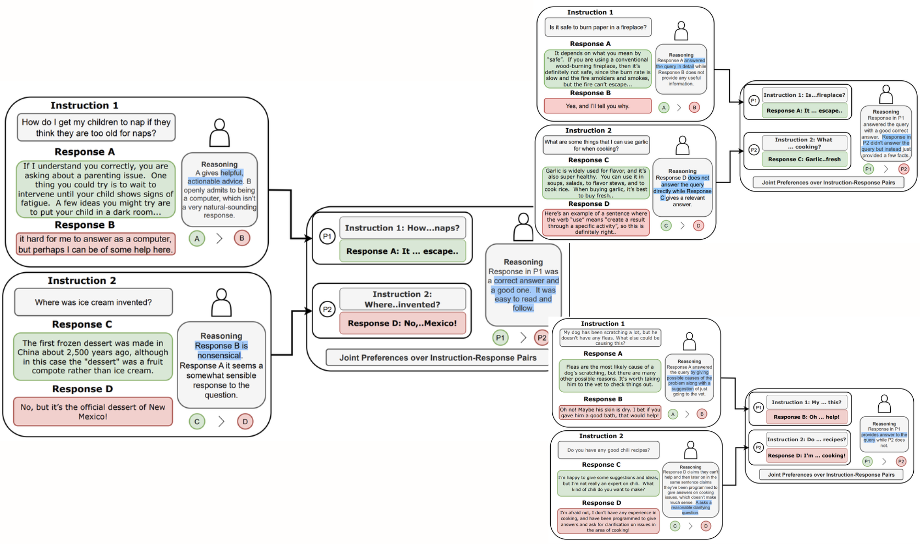 条件排名和联合排名之间的相互作用以及从人类注释者那里获得的推理。即使在条件排名中,一个响应优于另一个响应,但在联合排名中,情况可能会有所不同。来源:https://arxiv.org/abs/2404.00530
条件排名和联合排名之间的相互作用以及从人类注释者那里获得的推理。即使在条件排名中,一个响应优于另一个响应,但在联合排名中,情况可能会有所不同。来源:https://arxiv.org/abs/2404.00530
为了评估条件排名和联合排名之间的相互作用,分析了来自人工智能和人类注释者的反馈。分析显示,在 71% 的情况下,注释者可以在联合配置中做出决定性的选择,即使在条件配置中两个响应都被选择或拒绝。此外,注释者有时可能会偏爱在条件配置中先前被拒绝的响应,而不是首选的响应。
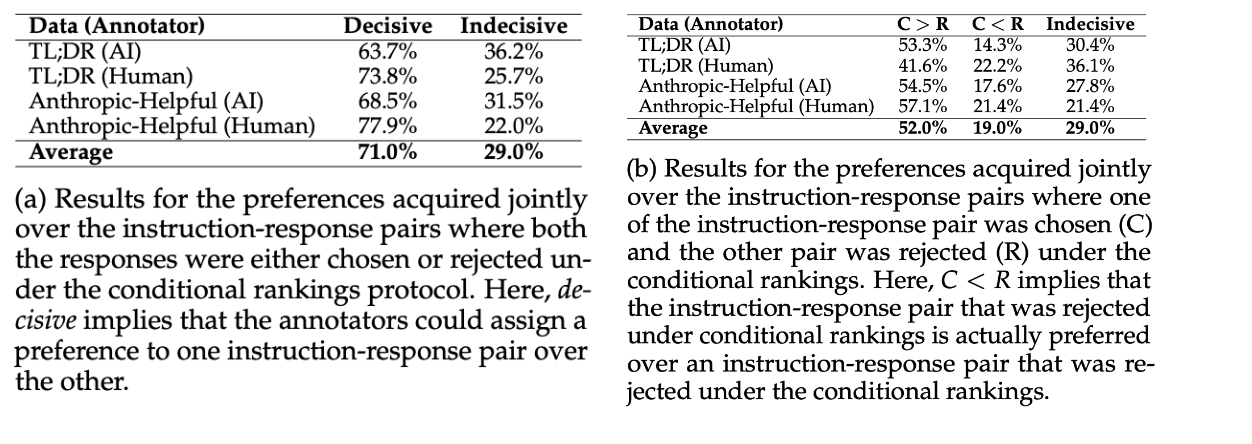 来源:https://arxiv.org/abs/2404.00530
来源:https://arxiv.org/abs/2404.00530
DOVE vs DPO
有关实验和结果的更多详细信息,请参阅原始论文和GitHub 存储库。
Mistral-7B 对齐的结果表明,DOVE 可以有效地利用条件偏好(视为具有相同上下文的联合偏好)和具有非相同上下文的联合偏好。
此外,据称,使用 DOVE 和指令-响应联合偏好数据训练的 LLM 在 TL;DR 和 Anthropic-Helpful 数据集上的获胜百分比分别比使用 DPO 训练的 LLM 高 5.2% 和 3.3%。
实验还突出了 DOVE 在仅使用指令-响应数据上的联合偏好对齐 LLM 的稳健性,而无需依赖条件偏好。这种方法不仅简化了对齐过程,还提高了模型在不同上下文中的性能。
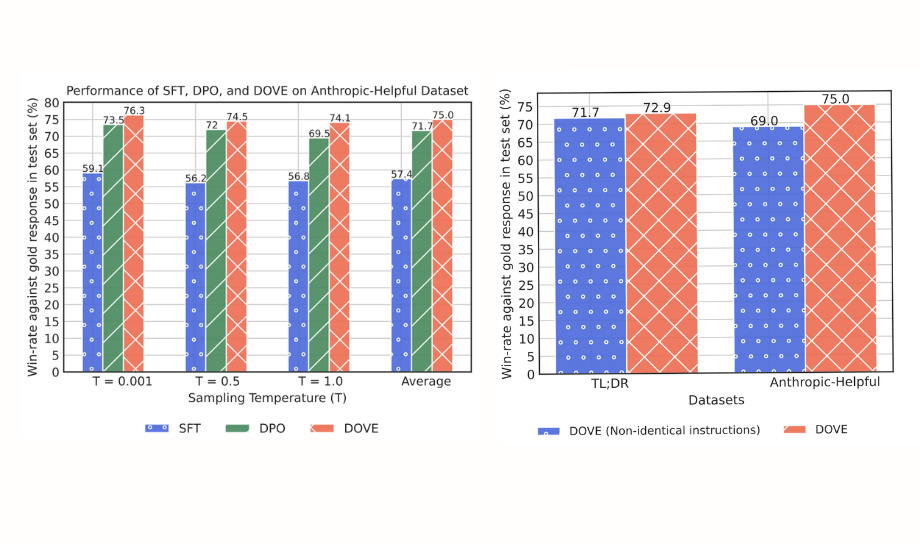 左图是使用 DOVE 偏好优化目标对齐 LLM 的结果。右图是使用 DOVE 的非相同指令的联合偏好的影响。来源:https://arxiv.org/abs/2404.00530
左图是使用 DOVE 偏好优化目标对齐 LLM 的结果。右图是使用 DOVE 的非相同指令的联合偏好的影响。来源:https://arxiv.org/abs/2404.00530
结论
总而言之,DOVE 是对大型语言模型对齐的一种富有洞察力的方法。它已被证明可以通过利用条件和联合反馈来准确捕捉更广泛的人类偏好,使其成为一种稳健的方法。虽然还需要进一步研究以了解其在不同场景和针对各种基准测试中的重要性,但这种方法为人类偏好如何运作以及我们应该面临的局限性提供了新的有益视角。
想了解更多?
这是关于 RLHF 替代方案的系列博客文章的第八篇。第一篇、第二篇、第三篇、第四篇、第五篇、第六篇、第七篇 和 第八篇 文章也可以在我们的网站上找到。请查阅概述以了解迄今为止提出的方法的优点和缺点。
Argilla 和 Mantis NLP 团队很乐意帮助您解答关于使用监督微调、强化学习或直接偏好优化训练 LLM 的准备步骤的任何问题。
Argilla 的 LLM 数据平台目前支持所有数据管理步骤,而 Mantis NLP 则为整个过程提供端到端支持。


